Changes in Novartis’ News Coverage
3 min
In the following notebook, we will be going over the capabilities of the Sturdy Statistics API by analyzing the past two years of Earnings Calls from Google, Microsoft, Amazon, NVIDA, and META.
Earnings Calls are a quarterly event during which a public company will discuss the results of the past quarter and take questions from its investors. These calls offer a unique candid glimpse into both the company’s outlooks as well as that of the industry as a whole. These calls are studied not only by investors, but also by sales, marketting and leadership teams. We chose this dataset because it is likely relevant to anyone looking at this notebook.
The recent popularity of Large Language Models has given rise to thousands of new unstructured data analysis, RAG question answering tools: however, for rigorous analyses these tools fall short. The richest insights are not the ones you knew to ask about, but rather the ones that are surfaced after rigorous analysis across time and across companies. In the following notebook, we demonstrate Sturdy Statistics’ ability to reveal structured insights for unstructured data, not with RAG or LLM black boxes but with rigorous, statistical analysis that leverages traditional tabular data structures.
We will be using an index from our pretrained gallery for this analysis. You can sign up on our website to generate your free (no payment info required) API key to run this notebook yourself and to upload your own data for analysis.
pip install sturdy-stats-sdk pandas numpy plotly
# pip install sturdy-stats-sdk pandas numpy plotly duckdb
from IPython.display import display, Markdown, Latex
import pandas as pd
import numpy as np
import plotly.express as px
from sturdystats import Index, Job
from pprint import pprint
index_id = "index_c6394fde5e0a46d1a40fb6ddd549072e" ## Optionally Replace with your own Index
index = Index(id=index_id) # Visit sturdystatistics.com to get your free API key ## Basic Utilities
px.defaults.template = "simple_white" # Change the template
px.defaults.color_discrete_sequence = px.colors.qualitative.Dark24 # Change color sequence
def procFig(fig, **kwargs):
fig.update_layout(plot_bgcolor= "rgba(0, 0, 0, 0)", paper_bgcolor= "rgba(0, 0, 0, 0)",
margin=dict(l=0,r=0,b=0,t=30,pad=0),
**kwargs
)
fig.layout.xaxis.fixedrange = True
fig.layout.yaxis.fixedrange = True
return fig
def displayText(df, highlight):
def processText(row):
t = "\n".join([ f'1. {r["short_title"]}: {int(r["prevalence"]*100)}%' for r in row["paragraph_topics"][:5] ])
x = row["text"]
res = []
for word in x.split(" "):
for term in highlight:
if term.lower() in word.lower() and "**" not in word:
word = "**"+word+"**"
res.append(word)
return f"<em>\n\n#### Result {row.name+1}/{df.index.max()+1}\n\n##### {row['ticker']} {row['pub_quarter']}\n\n"+ t +"\n\n" + " ".join(res) + "</em>"
res = df.apply(processText, axis=1).tolist()
display(Markdown(f"\n\n...\n\n".join(res)))The core building block in the Sturdy Statistics NLP toolkit is the Index. Each Index is a set of documents and metadata that has been structured or “indexed” by our hierarchical bayesian probability mixture model. Below we are connecting to an Index that has already been trained by our earnings transcripts integration.
index = Index(id="index_c6394fde5e0a46d1a40fb6ddd549072e") Found an existing index with id="index_c6394fde5e0a46d1a40fb6ddd549072e".You can see that we have imputed meaningful topics with interpretable names, and that each document can be understood according to its thematic content. Unlike LLM embeddings, each column in this representation corresponds to a meaningful, immediately interpretable concept, and most of the columns are zero. These properties greatly enhance the utility of our representation.
Our index maps this set of learned topics not only to each document, but also to every single word, sentence, paragraph, and group of documents in your data dataset, providing a powerful semantic indexing. We then expose the data through a set of standardized SQL APIs that integrate with existing structured data analysis toolkits.
The first API we will explore is the topicSearch API. This API provides a direct interface to the high level themes that our index extracts. You can call with no arguments to get a list of topics ordered by how often they occur in the dataset (prevalence). The resulting data is a structured rollup of all the data in the corpus. It aggregates the topic annotations across each word, paragraph, and document and generates high level semantic statistics.
The fields returned by this API include a unique topic identifier topic_id, a title assigned to the topic short_title, the number of paragraphs in which that topic is present in the dataset mentions and the percentage of the entire corpus that has been assigned to that topic prevalence.
df = index.topicSearch()
df.head()[["topic_id", "short_title", "topic_group_short_title", "mentions", "prevalence"]]| topic_id | short_title | topic_group_short_title | mentions | prevalence | |
|---|---|---|---|---|---|
| 0 | 159 | Accelerated Computing Systems | Technological Developments | 359.0 | 0.042775 |
| 1 | 139 | Consumer Behavior Insights | Growth Strategies | 585.0 | 0.033129 |
| 2 | 108 | Cloud Performance Metrics | Investment and Financials | 157.0 | 0.026985 |
| 3 | 115 | Zuckerberg on Business Strategies | Corporate Strategy | 420.0 | 0.026971 |
| 4 | 127 | Comprehensive Security Solutions | Investment and Financials | 146.0 | 0.023265 |
This structured information already reveals a lot of information into this dataset. We know what was talked about and how much it was discussed. We can see there is a field we didn’t yet mention: topic_group_short_title. While our topics tend to be extremely granular, our model also learns a structure on top of these topics that we designate a topic_group. A dataset can have anywhere from 100-500 topics, but will typically have only 20-50 topic groups. This hierarchy is extremly useful for organizing and exploring data in hierarchical formats such as sunbursts.
We visualize our this thematic data in the Sunburst visualization below. The inner circle of the sunburst is the title of the plot. The middle layer is the topic groups. And the leaf nodes are the topics that belong to the corresponding topic group. The size of each node is porportional to how often it shows up in the dataset.
topic_df = index.topicSearch()
topic_df["title"] = "Tech <br> Earnings Calls"
fig = px.sunburst(
topic_df,
path=["title", "topic_group_short_title", "short_title"],
values="prevalence",
hover_data=["topic_id", "mentions"]
)
procFig(fig, height=500).show()The topic search (along with our other semantic APIs) produce high level insights. In order to ensure these insights are trustworthy and actionable, we provide a mechanism to uncover the data that goes into the insights with our query API. This API shares a unified filtering engine with our higher level semantic APIs: as a result, any semantic rollup or insight aggregation can be instantly “unrolled”.
Among other parameters, the query API support filtering on topic_id. As a result, we can pick any topic As a result, any aggregate statistic can be immediately converted into the excerpt that comprise the statistic.
Let’s take the topic Generative AI in Search. We can uncover the topic metadata below and see that it was mentioned 137 times in the corpus.
TOPIC_ID = 5
row = topic_df.loc[topic_df.topic_id == TOPIC_ID]
row[["topic_id", "short_title", "mentions"]]| topic_id | short_title | mentions | |
|---|---|---|---|
| 49 | 5 | Generative AI in Search | 137.0 |
We can call the index.query API, passing in our topic_id as well as a set of parameters to ensure we do not cut off our results prematurely. We can see that we have 137 mentions returned, lining up exactly with our aggregate APIs. Below we display the first and last result of our search, as well as highlight a few terms to make the excerpts easier to read.
You will notice that accompanying each excerpt is a set of tags. These are the same tags that are returned in our topicSearch API. Here each tag corresponds to the percentage of the paragraph that it comprises.
df = index.query(topic_id=TOPIC_ID, max_excerpts_per_doc=20, limit=200) ## 200 is the single request limit
displayText(df.iloc[[0, -1]], highlight=["ai", "conversational", "search", "model", "multi"])
assert len(df) == row.iloc[0].mentions
We rolled out the biggest update to Windows 11 ever adding 150 new features including new AI-powered experiences in apps, like, Clipchamp, Paint, and Photos, and we introduced Copilot in Windows, the Everyday AI companion, which incorporates the context to the web, your work data and what you are doing on the PC to provide better assistance. We are seeing accelerated Windows 11 deployments worldwide from companies like BP, Eurowings, Kantar, and RBC. Finally, with Windows 365 Boot and Switch, we’re making it easier than ever for employees at companies like Crocs, Hamburg Commercial Bank, the ING Bank to get a personalized Windows 365 Cloud PC with Copilot on any device. Now on to security. The speed, scale, and sophistication of cyberattacks today is unparalleled and security is the number one priority for CIOs worldwide. We see high-demand for Security Copilot, the industry’s first and most advanced generative AI product, which is now seamlessly integrated with Microsoft 365 Defender. Dozens of organizations including Bridgewater, Fidelity National Financial, and Government of Alberta have been using Copilot in Preview, and early feedback has been positive. And we look forward to bringing Copilot to hundreds of organizations in the coming months as part of the new early access program, so they can improve the productivity of their own, security operation centers and stop threats at machine speeds.
…
Mark Zuckerberg: All right. So yes, on the Google and Microsoft partnerships, yes, I mean we work with them to have real-time information in Meta AI. It’s useful. I think it’s pretty different from search. We’re not working on search ads or anything like that. I think this will end up being a pretty different business.
In addition to power our semantic APIs, Sturdy Statistics’ probability model also powers our statistical search engine. When you submit a search query, your index model maps your query to its thematic contents. Because our models return structured Bayesian likelihoods, we are able use a statistically meaningful scoring metric called hellinger distance to score each search candidate. Unlike cosine distance whose values are not well defined and can be used only to rank, the hellinger distance score defines the percentage of a document that ties directly to your theme.
This well defined score enables not only search ranking, but semantic search filter as well with the ability to define a hand-selected hard cutoff
We are using two new capabilities in the Query API: filtering and search. Our Query API supports arbitrary sql conditions in the filter. We leverage DuckDB under the hood and support all of DuckDB’s sql querying syntax.
In addition to accepting a search term, our Query API accepts a semantic_search_cutoff and a semantic_search_weight. The semantic_search_cutoff is a value between 0-1. The value corresponds to the percentage of the paragraph that focuses on the search term. Our value of .1 below means that at least 10% of the paragraph must focus on our search term. This enables flexible semantic filtering capabilities while providing sensible defaults out of the box.
The semantic_search_weight dictates the weight placed on our thematic search score vs our TF-IDF weighted exact match score. Each use case is different and our API provides the flexibility to tune you indices according to your use-case while providing sensible defaults out of the box.
In the examples below, you’ll notice that our index surfaced paragraphs that matched not only on FX, but also on foreign exchange, pressures, and slowdown.
SEARCH_QUERY = "fx"
FILTER = "ticker='GOOG'"
df = index.query(SEARCH_QUERY, filters=FILTER,
semantic_search_cutoff=.1, semantic_search_weight=.3,
max_excerpts_per_doc=20, limit=200)
displayText(df.iloc[[0, -1]], highlight=["fx", "foreign", "exchange", "stabilization", "pressures", "slowdown", "pullback"])
Sundar Pichai: Thank you, Jim, and good afternoon, everyone. It’s clear that after a period of significant acceleration in digital spending during the pandemic, the macroeconomic climate has become more challenging. We continue to have an extraordinary business and provide immensely valuable services for people and our partners. For example, during the World Cup final on December 18, Google Search saw its highest query per second volume of all time. And beyond our advertising business, we have strong momentum in Cloud, YouTube subscriptions and hardware.
…
Philipp Schindler: Yes. Look, this is a great question, first of all. I mean, let’s start with the fact that YouTube performance was very strong in this quarter. And on Shorts specifically in the U.S., I mentioned how the monetization rate of Shorts relative to in-stream viewing has more than doubled in the last 12 months. I think that’s what you were referring to. And yes, we’re obviously very happy with this development.
The exact match search only hits on a single result. We are missing 20/27 of the matching exchanges because of the restrictiveness of exact matching rules.
## Setting semantic search weight to 0 forces an exact match only search.
df = index.query(SEARCH_QUERY, filters=FILTER, semantic_search_cutoff=.1, semantic_search_weight=0, max_excerpts_per_doc=20, limit=200)
displayText(df.iloc[[0, -1]], highlight=["fx", "foreign", "exchange", "stabilization", "pressures", "slowdown", "pullback"])
I’ll highlight 2 other factors that affected our Ads business in Q4. Ruth will provide more detail. In Search and Other, revenues grew moderately year-over-year, excluding the impact of FX, reflecting an increase in retail and travel, offset partially by a decline in finance. At the same time, we saw further pullback in spend by some advertisers in Search in Q4 versus Q3. In YouTube and Network, the year-over-year revenue declines were due to a broadening of pullbacks in advertiser spend in the fourth quarter.
…
Anat Ashkenazi: And on the question regarding my comment on lapping the strength in financial services, this is primarily related to the structural changes with regards to insurance, it is more specifically within financial services, it was the insurance segment and we saw that continue, but it was a one-time kind of a step up and then we saw it throughout the year. I am not going to give any specific numbers as to what we expect to see in 2025, but I am pleased with the fact that we are seeing and continue to see strength across really all verticals including retail and exiting the year in a position of strength. If anything, I would highlight as you think about the year, the comments I have made about the impact of FX, as well as the fact that we have one less day of revenue in Q1.
In our FX search query, the data very useful, but that’s a lot to read and digest. Let’s try to summarize that data into a high level overview. Because our Topic Search API supports the exact same parameters as our Query API, we can instantly switch between high level insights and granular data.
df = index.topicSearch(SEARCH_QUERY, FILTER, semantic_search_cutoff=.1)
df["search_query"] = SEARCH_QUERY
fig = px.sunburst(df, path=["search_query", "short_title"], values="prevalence", hover_data=["topic_id"],)
procFig(fig, height=500).show()So far we have gone over topicSearch a high level semantic API and query a lower level search API. Now we are going to cover our final view of the data: the queryMeta API.
Our queryMeta API exposes the underlying tabular data strucutres that power both our topicSearch and query APIs. Specifically, we expose our underlying doc and paragraph tables. Each row in doc contains any metadata you uploaded alongside your unstructured data. Each row also contains the topic annotations we mentioned in a structured sparse format. Each row in paragraph contains all the same metadata fields as doc as well as its own set of local topic annotations. Because paragraphs are shorter, their topics tend to be even sparser than the document level topics, and are leverage for our mentions tallies in topicSearch.

Similar to our topicSearch and query APIs, Sturdy Statistics integrates its semantic search directly into its sql API, enabling powerful sql analyses with minimal complexity. The results leverage the same statistical search engine as our query API and exposes the same search tuning parameters. The high level aggregations should always perfectly line up with the underlying data and results.
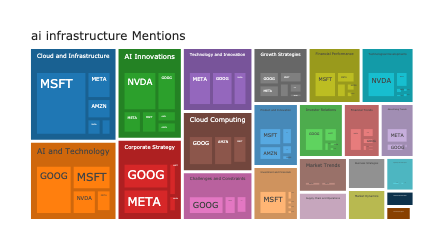
SEARCH_QUERY = "ai infrastructure"
df = index.queryMeta("SELECT ticker, count(*) as mentions FROM paragraph GROUP BY ticker",
search_query=SEARCH_QUERY, semantic_search_cutoff=.1)
fig = px.bar(df, x="ticker", y="mentions", title=f"Mentions of '{SEARCH_QUERY}'")
procFig(fig, title_x=.5)df = index.queryMeta("SELECT ticker, pub_quarter, count(*) as mentions FROM paragraph GROUP BY ticker, pub_quarter ORDER BY pub_quarter",
search_query=SEARCH_QUERY, semantic_search_cutoff=.1)
fig = px.bar(df, x="pub_quarter", y="mentions", color="ticker", title=f"Mentions of '{SEARCH_QUERY}'")
procFig(fig, title_x=.5).show()Let’s do a quick spot check verification: let’s pull out all the excerpts from AMZN’s latest quarter 2025Q1 and ensure that the number line up. According to the graph, there should be 6 results.
df = index.query(SEARCH_QUERY, filters="ticker='AMZN' and pub_quarter='2025Q1'", max_excerpts_per_doc=20, semantic_search_cutoff=.1)
displayText(df.iloc[[0, -1]], ["ai", "capex", "generative" ])
assert len(df) == 4 ## We see that the mentions in the plot line up with the mentions in the graph
In areas like Alexa, health care, and grocery, as well as satellites in the coming months. As a reminder, we currently expense the majority of the cost associated with the development of our satellite network. We will capitalize certain costs once the service achieves commercial viability, including sales to customers. Moving next to our AWS segment, revenue was $28.8 billion, an increase of 19% year over year. AWS now has an annualized revenue run rate of $115 billion. During the fourth quarter, we continue to see growth in both generative AI and non-generative AI offerings. As companies turn their attention to newer initiatives, bring more workloads to the cloud, restart or accelerate existing migrations from on-premise to the cloud, and tap into the power of generative AI. Customers recognize to get the full benefit of generative AI, they have to move to the cloud. AWS reported operating income of $10.6 billion, an increase of $3.5 billion year over year. This is the result of strong growth, innovation in our software and infrastructure to drive efficiencies, and continued focus on cost control across the business. As we’ve said in the past, we expect AWS operating margins to fluctuate over time, driven in part by the level of investments we’re making. Additionally, we increased the estimated useful life of our servers starting in 2024, which contributed approximately 200 basis points to the AWS margin increase year over year in Q4.
…
And we have a kind of next wave that we’re starting to work on now. But I think this will be a many-year effort as we continue to tune different parts of our fulfillment network where we can use robotics. And we actually don’t think there are that many things that we can’t improve the experience with robotics. On your other question, which is about how we might use AI in other areas of the business than AWS, maybe more in, I think you asked about our retail business. The way I would think about it is that there’s kind of two macro buckets of how we see people, both ourselves inside Amazon, as well as other companies using AWS, how we see them getting value out of AI today. The first macro bucket, I would say, is really around productivity and cost savings. And, in many ways, this is the lowest hanging fruit in AI. And you see that all over the place in our retail business. For instance, if you look at customer service, and you look at the chatbot that we’ve built, we completely rearchitected it with generative AI. It’s delivering; it already had pretty high satisfaction. It’s delivering 500 basis points better satisfaction from customers with the new generative AI-infused chatbot.
We discussed our sparse topic data structures above. Now we will leverage those datastructures to explore how much the topic of Generative AI in Search (topic_id 5) has been discussed Quarter by Quarter.
The SQL statement below is a standard group by. The only new content is the line: (sparse_list_extract({TOPIC_ID+1}, c_mean_avg_inds, c_mean_avg_vals) > 2.00)::INT. We store our arrays in a sparse format of a list of indices and a list of values. This format provides significant storage and performance optimizations. We use a defined set of sparse functions to work with this data.
Below we give it the fields c_mean_avg_inds and c_mean_avg_vals. The original c_mean_avg array is a count of the number of words in each paragraph that have been assigned to a topic. The mean_avg denotes that this value has been accumulated over several hundred MCMC samples. This sampling has numerous benefits and is also why our counts are not integers (a very common question we receive).
TOPIC_ID = 5
df = index.queryMeta(f"""
SELECT
pub_quarter,
sum(
(sparse_list_extract({TOPIC_ID+1}, c_mean_avg_inds, c_mean_avg_vals) > 2.00)::INT
) as mentions
FROM paragraph
GROUP BY pub_quarter
ORDER BY pub_quarter
""", search_query=SEARCH_QUERY, semantic_search_cutoff=.1)
fig = px.line(
df, x="pub_quarter", y="mentions",
title=f"Mentions of 'Generative AI in Search' + '{SEARCH_QUERY}'",
line_shape="hvh",
)
procFig(fig, title_x=.5).show()As always, we can verify every aspect of our high level insights by returning to the data.
df = index.query(SEARCH_QUERY, topic_id=TOPIC_ID, filters="pub_quarter='2023Q3'", semantic_search_cutoff=.1)
assert len(df) == 2
displayText(df.iloc[[0,-1]], ["ai", "search", "web", "engineering", "grow", "demand"])
Our new generative AI offerings are expanding our total addressable market and winning new customers. We are seeing strong demand for the more than 80 models, including third-party and popular open source in our Vertex, Search and Conversational AI platforms with a number of customers growing more than 15x from April to June.
…
Our approach to AI in ads remains grounded in understanding what drives real value for businesses right now and what’s most helpful for users. Advertisers tell us they’re looking for more assistive experience to get set up with us faster. So at GML, we launched a new conversational experience in Google Ads powered by a LLM tuned specifically from ads data to make campaign construction easier than ever.
from sturdystats import Index
index = Index("Custom Analysis")
index.upload(df.to_dict("records"))
index.commit()
index.train()
# Ready to Explore
index.topicSearch()